鴻海科技日大解密!MIH平台的未來機會在哪裡?發表三款電動車是真的嗎?
Monday, January 31, 2022
Sunday, January 30, 2022
[c++] 动态内存
C++ 动态内存
C++ 程序中的内存分为两个部分:
栈:在函数内部声明的所有变量都将占用栈内存。
堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。
很多时候,您无法提前预知需要多少内存来存储某个定义变量中的特定信息,所需内存的大小需要在运行时才能确定。
在 C++ 中,您可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。
如果您不需要动态分配内存,可以使用 delete 运算符,删除之前由 new 运算符分配的内存
new 和 delete 运算符
下面是使用 new 运算符来为任意的数据类型动态分配内存的通用语法:
==============================================
new data-type;
==============================================
在这里,data-type 可以是包括数组在内的任意内置的数据类型,也可以是包括类或结构在内的用户自定义的任何数据类型。让我们先来看下内置的数据类型。例如,我们可以定义一个指向 double 类型的指针,然后请求内存,该内存在执行时被分配。我们可以按照下面的语句使用 new 运算符来完成这点:
==============================================
double* pvalue = NULL; // 初始化为 null 的指针
pvalue = new double; // 为变量请求内存
==============================================
如果自由存储区已被用完,可能无法成功分配内存。所以建议检查 new 运算符是否返回 NULL 指针,并采取以下适当的操作:
==============================================
double* pvalue = NULL;
if( !(pvalue = new double ))
{
cout << "Error: out of memory." <<endl;
exit(1);
==============================================
malloc() 函数在 C 语言中就出现了,在 C++ 中仍然存在,但建议尽量不要使用 malloc() 函数。new 与 malloc() 函数相比,其主要的优点是,new 不只是分配了内存,它还创建了对象。
在任何时候,当您觉得某个已经动态分配内存的变量不再需要使用时,您可以使用 delete 操作符释放它所占用的内存,如下所示:
==============================================
delete pvalue; // 释放 pvalue 所指向的内存
==============================================
下面的实例中使用了上面的概念,演示了如何使用 new 和 delete 运算符:
==============================================
#include <iostream>
using namespace std;
int main ()
{
double* pvalue = NULL; // 初始化为 null 的指针
pvalue = new double; // 为变量请求内存
*pvalue = 29494.99; // 在分配的地址存储值
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // 释放内存
return 0;
}
==============================================
当上面的代码被编译和执行时,它会产生下列结果:
==============================================
Value of pvalue : 29495
==============================================
数组的动态内存分配
假设我们要为一个字符数组(一个有 20 个字符的字符串)分配内存,我们可以使用上面实例中的语法来为数组动态地分配内存,如下所示:
char* pvalue = NULL; // 初始化为 null 的指针
pvalue = new char[20]; // 为变量请求内存
要删除我们刚才创建的数组,语句如下:
delete [] pvalue; // 删除 pvalue 所指向的数组
下面是 new 操作符的通用语法,可以为多维数组分配内存,如下所示:
==============================================
int ROW = 2;
int COL = 3;
double **pvalue = new double* [ROW]; // 为行分配内存
// 为列分配内存
for(int i = 0; i < COL; i++) {
pvalue[i] = new double[COL];
}
==============================================
释放多维数组内存:
==============================================
for(int i = 0; i < COL; i++) {
delete[] pvalue[i];
}
delete [] pvalue;
==============================================
对象的动态内存分配
对象与简单的数据类型没有什么不同。例如,请看下面的代码,我们将使用一个对象数组来理清这一概念:
==============================================
#include <iostream>
using namespace std;
class Box
{
public:
Box() {
cout << "调用构造函数!" <<endl;
}
~Box() {
cout << "调用析构函数!" <<endl;
}
};
int main( )
{
Box* myBoxArray = new Box[4];
delete [] myBoxArray; // Delete array
return 0;
}
==============================================
如果要为一个包含四个 Box 对象的数组分配内存,构造函数将被调用 4 次,同样地,当删除这些对象时,析构函数也将被调用相同的次数(4次)。
当上面的代码被编译和执行时,它会产生下列结果:
调用构造函数!
调用构造函数!
调用构造函数!
调用构造函数!
调用析构函数!
调用析构函数!
调用析构函数!
调用析构函数!
[c++] 文件和流
iostream 标准库,它提供了 cin 和 cout 方法分别用于从标准输入读取流和向标准输出写入流。
如何从文件读取流和向文件写入流。这就需要用到 C++ 中另一个标准库 fstream,它定义了三个新的数据类型:
| 数据类型 | 描述 |
|---|---|
| ofstream | 该数据类型表示输出文件流,用于创建文件并向文件写入信息。 |
| ifstream | 该数据类型表示输入文件流,用于从文件读取信息。 |
| fstream | 该数据类型通常表示文件流,且同时具有 ofstream 和 ifstream 两种功能,这意味着它可以创建文件,向文件写入信息,从文件读取信息。 |
要在 C++ 中进行文件处理,必须在 C++ 源代码文件中包含头文件 <iostream> 和 <fstream>。
reference
https://www.w3cschool.cn/cpp/cpp-files-streams.html
Saturday, January 29, 2022
[c++] 多態
https://www.w3cschool.cn/cpp/cpp-polymorphism.html
导致错误输出的原因是,调用函数 area() 被编译器设置为基类中的版本,这就是所谓的静态多态,或静态链接 - 函数调用在程序执行前就准备好了。有时候这也被称为早绑定,因为 area() 函数在程序编译期间就已经设置好了。
虚函数
虚函数 是在基类中使用关键字 virtual 声明的函数。在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数。
我们想要的是在程序中任意点可以根据所调用的对象类型来选择调用的函数,这种操作被称为动态链接,或后期绑定。
纯虚函数
您可能想要在基类中定义虚函数,以便在派生类中重新定义该函数更好地适用于对象,但是您在基类中又不能对虚函数给出有意义的实现,这个时候就会用到纯虚函数。
我们可以把基类中的虚函数 area() 改写如下:
// pure virtual function
virtual int area() = 0;
Tuesday, January 25, 2022
[Package Image] Make Android userdata
1. 透過full pkg 升級
2. 升級完成後,等待首次開機完成
3. 進入MBOOT mode
4. 透過指令,將 emmc 資料寫入USB中(16G)
mmc dd mmc2usb
5. 透過 imageusb 將整個 usb 轉成 bin 檔。
6. 由 BIN 中,將 userdata 抽離出來
參考 packing_emmc_16G_writer.scr
output/rel/img/00.bin 0x0 NON NON 0x0000000084210000 0x000000011b200000
起始位置 0x84210000= 2216755200
如果bs=512,因此skip要設定為4329600
分割區大小 0x11b200000 = 4750049280 也就是4.7G
如果bs=512,count要設定為9277440。
又因為使用imageusb的關係,所以前面512為軟體資訊,因此,正確起始位置需要+1
再透過linux dd command
dd if=fullemmc.bin of=userdata.img bs=512 count=9277440 skip=4329601
7. 檢查內容
mkdir newuserdata/
sudo mount -t ext4 userdata_speedup.img newuserdata/
進入查看
sudo umount newuserdata/
8. 將userdata.img壓縮後,放到T91打包的工具內。
git clone ssh://url/t91_release_tool
/t91_release_tool/upstreamPKGPa/input/userdata_speedup.img.gz
/t91_release_tool/upstreamPKGSa/input/userdata_speedup.img.gz
9. 執行打包,build code
Monday, January 24, 2022
[css] Picture Animation
Old
=========================================================================
position: absolute;
overflow: hidden;
background-image:url("assets/bg_1.jpg");
background-image:url("assets/bg_2.jpg");
background-image:url("assets/bg_3.jpg");
background-image:url("assets/bg_afternoon_1.jpg");
/*animation:fadeInOut 360s linear 2s infinite alternate;*/
/*animation: example 5s linear 2s infinite alternate;*/
animation-name: fadeInOut;
animation-duration: 360s;
animation-timing-function: ease-in-out; /*linear;*/
animation-delay: 0s;
animation-iteration-count: infinite;
/*animation-direction: alternate; */
}
@keyframes fadeInOut {
0% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_1.jpg");}
11% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_2.jpg");}
22% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_3.jpg");}
33% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_1.jpg");}
44% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_2.jpg");}
55% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_3.jpg");}
66% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_4.jpg");}
77% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_5.jpg");}
88% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_6.jpg");}
100% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_1.jpg");}
}
=========================================================================
New
=========================================================================
overflow: hidden;
background-image:url("assets/bg_1.jpg"),
url("assets/bg_2.jpg"),
url("assets/bg_3.jpg"),
url("assets/bg_afternoon_1.jpg"),
url("assets/bg_afternoon_2.jpg"),
url("assets/bg_afternoon_3.jpg"),
url("assets/bg_afternoon_4.jpg"),
url("assets/bg_afternoon_5.jpg"),
url("assets/bg_afternoon_6.jpg");
animation: fadeInOut 360s ease-in-out 0s infinite;
/*animation:fadeInOut 360s linear 2s infinite alternate;*/
/*animation: example 5s linear 2s infinite alternate;*/
//animation-name: fadeInOut;
//animation-duration: 360s;
//animation-timing-function: ease-in-out; /*linear;*/
//animation-delay: 0s;
//animation-iteration-count: infinite;
/*animation-direction: alternate; */
}
@keyframes fadeInOut {
0% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_1.jpg");}
11% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_2.jpg");}
22% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_3.jpg");}
33% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_1.jpg");}
44% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_2.jpg");}
55% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_3.jpg");}
66% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_4.jpg");}
77% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_5.jpg");}
88% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_afternoon_6.jpg");}
100% {Transition: background-image 1s ease-in-out;
background-image:url("assets/bg_1.jpg");}
}
=========================================================================
However, MDN spec [2]
*doesn't* indicate {{background-image}} is an *animatable* property. So it
might be better to use CSS animation with another property e.g. {{opacity}}.
Also, from browser perspective, every operation setting
the background-image will trigger a repaint which is expensive in rendering.
[1] https://developer.mozilla.org/en-US/docs/Web/CSS/background-image
[2] https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_animated_properties
Sunday, January 23, 2022
[c++] 内联函数
int max(int a, int b)
{
return a > b ? a : b;
}
这样写成函数有一个潜在的缺点:调用函数比求解等价表达式要慢得多。在大多数的机器上,调用函数都要做很多工作:调用前要先保存寄存器,并在返回时恢复,复制实参,程序还必须转向一个新位置执行。
在C++中可以使用内联函数,其目的是为了提高函数的执行效率,通常与类一起使用。如果一个函数是内联的,那么在编译时,编译器会把该函数的代码副本放置在每个调用该函数的地方。
对内联函数进行任何修改,都需要重新编译函数的所有客户端,因为编译器需要重新更换一次所有的代码,否则将会继续使用旧的函数。
如果想把一个函数定义为内联函数,则需要在函数名前面放置关键字 inline,在调用函数之前需要对函数进行定义。如果已定义的函数多于一行,编译器会忽略 inline 限定符。
在类定义中的定义的函数都是内联函数,即使没有使用 inline 说明符。
有了内联函数,就能像调用一个函数那样方便地重复使用一段代码,而不需要付出执行函数调用的额外开销。很显然,使用内联函数会是最终可执行程序的体积增加。以空间换取时间,或消耗时间来增加空间,这是计算机学科中常用的方法。
[c++] 友元函数
权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。
友元函数没有 this 指针,因为友元不是类的成员。只有成员函数才有 this 指针。
[c++] 拷贝构造函数
如果在类中没有定义拷贝构造函数,编译器会自行定义一个。如果类带有指针变量,并有动态内存分配,则它必须有一个拷贝构造函数。拷贝构造函数的最常见形式如下:
classname (const classname &obj) {
// 构造函数的主体
}
==========================================================================
#include <iostream>
using namespace std;
class Line
{
public:
int getLength( void );
Line( int len ); // 简单的构造函数
Line( const Line &obj); // 拷贝构造函数
~Line(); // 析构函数
private:
int *ptr;
};
// 成员函数定义,包括构造函数
Line::Line(int len)
{
cout << "Normal constructor allocating ptr" << endl;
// 为指针分配内存
ptr = new int;
*ptr = len;
}
Line::Line(const Line &obj)
{
cout << "Copy constructor allocating ptr." << endl;
ptr = new int;
*ptr = *obj.ptr; // copy the value
}
Line::~Line(void)
{
cout << "Freeing memory!" << endl;
delete ptr;
}
int Line::getLength( void )
{
return *ptr;
}
void display(Line obj)
{
cout << "Length of line : " << obj.getLength() <<endl;
}
// 程序的主函数
int main( )
{
Line line1(10);
Line line2 = line1; // 这里也调用了拷贝构造函数
display(line1);
display(line2);
return 0;
}
==================================================================
Normal constructor allocating ptr
Copy constructor allocating ptr.
Copy constructor allocating ptr.
Length of line : 10
Freeing memory!
Copy constructor allocating ptr.
Length of line : 10
Freeing memory!
Freeing memory!
Freeing memory!
Saturday, January 22, 2022
[c++] 引用
引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。
C++ 引用 vs 指针
引用很容易与指针混淆,它们之间有三个主要的不同:
- 不存在空引用。引用必须连接到一块合法的内存。指针变量编译器会为它分配内存
- 一旦引用被初始化为一个对象,就不能被指向到另一个对象。指针可以在任何时候指向到另一个对象。
- 引用必须在创建时被初始化。指针可以在任何时间被初始化。
C++ 中创建引用
试想变量名称是变量附属在内存位置中的标签,您可以把引用当成是变量附属在内存位置中的第二个标签。因此,您可以通过原始变量名称或引用来访问变量的内容。
引用通常用于函数参数列表和函数返回值。下面列出了 C++ 程序员必须清楚的两个与 C++ 引用相关的重要概念:
C++ 支持把引用作为参数传给函数,这比传一般的参数更安全
通过使用引用来替代指针,会使 C++ 程序更容易阅读和维护。C++ 函数可以返回一个引用,方式与返回一个指针类似
Wednesday, January 19, 2022
Monday, January 17, 2022
[git svn patch quilt ] SVN to Git
安裝svn軟體
apt install subverion
下載code
svn co https://xxxxx/xxxx
如果出現
svn: E120171: Error running context: An error occurred during SSL communication
修改
/usr/lib/ssl/openssl.cnf
最上方
openssl_conf = default_conf
最下面
[ default_conf ]
ssl_conf = ssl_sect
[ssl_sect]
system_default = ssl_default_sect
[ssl_default_sect]
MinProtocol = TLSv1
CipherString = DEFAULT:@SECLEVEL=1
svn co --username david https://192.168.1.229/svn/sd/trunk/abc_2k22_NOT92333/
git svn clone https://192.168.1.229/svn/sd/trunk/abc_2k22_NOT92333/
git svn clone --username david https://192.168.1.229/svn/sd/trunk/abc_2k22_
2083 git remote add origin ssh://Abbylliu@192.16.0.31:29418/2K22_NETPHONE
2084 git push origin master
2085 git push -f origin master
Sunday, January 16, 2022
[c++] 指標
C++ 支持空指针。NULL 指针是一个定义在标准库中的值为零的常量。
可以对指针进行四种算术运算:++、--、+、-
指针和数组之间有着密切的关系。
============================================
#include <iostream>
using namespace std;
const int MAX = 3;
int main ()
{
int var[MAX] = {10, 100, 200};
cout<<var<<endl;
cout<<*var<<endl;
for (int i = 0; i < MAX; i++)
{
*var = i; // 这是正确的语法
cout<<*var<<endl;
cout<<i<<endl;
cout<<&i<<endl;
cout<<var<<endl;
*(var+1)=500;
cout<<*(var+1)<<endl;
//var++; // 这是不正确的
}
return 0;
}
=========================================
0x7ffda7291170
10
0
0
0x7ffda729116c
0x7ffda7291170
500
1
1
0x7ffda729116c
0x7ffda7291170
500
2
2
0x7ffda729116c
0x7ffda7291170
500
=========================================
可以定义用来存储指针的数组。
C++ 允许指向指针的指针。
通过引用或地址传递参数,使传递的参数在调用函数中被改变。
C++ 允许函数返回指针到局部变量、静态变量和动态内存分配。
Thursday, January 13, 2022
[c] epoll和select
在高并发服务器中,轮询I/O是最耗时间的操作之一,select 和 epoll 的性能谁的性能更高
select的调用复杂度是线性的,即O(n)
举个例子,一个保姆照看一群孩子,如果把孩子是否需要尿尿比作网络IO事件,select的作用就好比这个保姆挨个询问每个孩子:你要尿尿吗?如果孩子回答是,保姆则把孩子拎出来放到另外一个地方。当所有孩子询问完之后,保姆领着这些要尿尿的孩子去上厕所(处理网络IO事件)。 还是以保姆照看一群孩子为例
select本质上是通过设置或检查存放fd标志位的数据结构进行下一步处理。 这带来缺点:
- 单个进程可监视的fd数量被限制,即能监听端口的数量有限 单个进程所能打开的最大连接数有
FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试 一般该数和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认1024个,64位默认2048。

- 对socket是线性扫描,即轮询,效率较低: 仅知道有I/O事件发生,却不知是哪几个流,只会无差异轮询所有流,找出能读数据或写数据的流进行操作。同时处理的流越多,无差别轮询时间越长 - O(n)。
当socket较多时,每次select都要通过遍历FD_SETSIZE个socket,不管是否活跃,这会浪费很多CPU时间。如果能给 socket 注册某个回调函数,当他们活跃时,自动完成相关操作,即可避免轮询,这就是epoll与kqueue。
1.1 调用过程
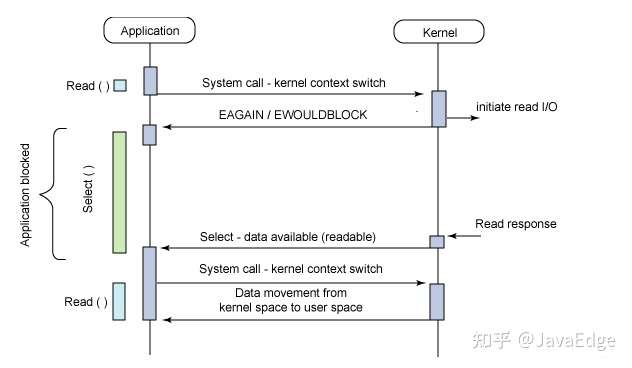
epoll机制
保姆不再需要挨个的询问每个孩子是否需要尿尿。取而代之的是,每个孩子如果自己需要尿尿的时候,自己主动的站到事先约定好的地方,而保姆的职责就是查看事先约定好的地方是否有孩子。如果有小孩,则领着孩子去上厕所(网络事件处理)。
select单个进程可监视的fd数量受到限制 epoll和select都可以实现同时监听多个I/O事件的状态。
select 基于轮训机制
epoll基于操作系统支持的I/O通知机制 epoll支持水平触发和边沿触发两种模式
[Linux Kernel softirq、tasklet、workqueue之間的區別
softirq
軟中斷支持SMP,同一個 softirq 可以在不同的CPU上同時運行,softirq 必須是可重入的。
軟中斷是在編譯期間靜態分配的,它不像 tasklet 那樣能被動態的註冊或去除。
kernel/softirq.c中定義了一個包含 32 個 softirq_action結構體的數組。每個被註冊的軟中斷都佔據該數組的一項。因此最多可能有32個軟中斷。
2.6版本的內核中定義了六個軟中斷:HI_SOFTIRQ、TIMER_SOFTIRQ、NET_TX_SOFTIRQ、NET_RX_SOFTIRQ、SCSI_SOFTIRQ、TASKLET_SOFTIRQ。
軟中斷的特性:
1).一個軟中斷不會搶佔另外一個軟中斷。
2).唯一可以搶佔軟中斷的是中斷處理程序。
3).其他軟中斷(包括相同類型的)可以在其他的處理其上同時執行。
4).一個註冊的軟中斷必須在被標記後才能執行。
5).軟中斷不可以自己休眠(即調用可阻塞的函數或sleep等)。
6).索引號小的軟中斷在索引號大的軟中斷之前執行。
tasklet
引入tasklet,最主要的是考慮支持SMP,提高SMP多個cpu的利用率;兩個相同的tasklet決不會同時執行。
tasklet可以理解爲softirq的派生,所以它的調度時機和軟中斷一樣。對於內核中需要延遲執行的多數任務都可以用tasklet來完成,由於同類tasklet本身已經進行了同步保護,所以使用tasklet比軟中斷要簡單的多,而且效率也不錯。tasklet把任務延遲到安全時間執行的一種方式,在中斷期間運行,即使被調度多次,tasklet也只運行一次,不過tasklet可以在SMP系統上和其他不同的tasklet並行運行。在SMP系統上,tasklet還被確保在第一個調度它的CPU上運行,因爲這樣可以提供更好的高速緩存行爲,從而提高性能。
tasklet的特性:.不允許兩個兩個相同類型的tasklet同時執行,即使在不同的處理器上。
work queue
如果推後執行的任務需要睡眠,那麼就選擇工作隊列。另外,如果需要用一個可以重新調度的實體來執行你的下半部處理,也應該使用工作隊列。它是唯一能在進程上下文運行的下半部實現的機制,也只有它纔可以睡眠。這意味着在需要獲得大量的內存時、在需要獲取信號量時,在需要執行阻塞式的I/O操作時,它都會非常有用。
work queue造成的開銷最大,因爲它要涉及到內核線程甚至是上下文切換。這並不是說work queue的低效,但每秒鐘有數千次中斷,就像網絡子系統時常經歷的那樣,那麼採用其他的機制可能更合適一些。 儘管如此,針對大部分情況工作隊列都能提供足夠的支持。
工作隊列特性:
1).工作隊列會在進程上下文中執行!
2).可以阻塞。(前兩種機制是不可以阻塞的)
3).可以被重新調度。(前兩種只可以被中斷處理程序打斷)
4).使用工作隊列的兩種形式:
1>缺省工作者線程(works threads)
2>自建的工作者線程
5).在工作隊列和內核其他部分之間使用鎖機制就像在其他的進程上下文一樣。
6).默認允許響應中斷。
7).默認不持有任何鎖。
4、softirq和tasklet共同點
軟中斷和tasklet都是運行在中斷上下文中,它們與任一進程無關,沒有支持的進程完成重新調度。所以軟中斷和tasklet不能睡眠、不能阻塞,它們的代碼中不能含有導致睡眠的動作,如減少信號量、從用戶空間拷貝數據或手工分配內存等。也正是由於它們運行在中斷上下文中,所以它們在同一個CPU上的執行是串行的,這樣就不利於實時多媒體任務的優先處理。
Bottom Half 機制比較表
| Bottom Half | 執行環境 | 序列執行 |
|---|---|---|
| Softirq | 中斷環境 | 無 |
| Tasklet | 中斷環境 | 同類型不同同時執行 |
| Work queues | 程序環境 | 無 |
簡單地說,一般的驅動程序的編寫者需要做兩個選擇。 首先,你是不是需要一個可調度的實體來執行需要推後完成的工作――從根本上來說,有休眠的需要嗎?要是有,工作隊列就是你的惟一選擇。 否則最好用tasklet。要是必須專注於性能的提高,那麼就考慮softirq。
Bottom Halves 間的同步鎖定
Tasklets 的一大優點就是:
在系統的其他處理上,相同的 tasklets 也不能同時執行。所以後不用擔心相同 tasklet 的並行問題。但是不同的 tasklets 間卻有可能共享資料,就必須引入適當的同步鎖定才行。
softirqs 完全沒有序列執行的限制,相同的 softirq 可以同時執行,所有共享的資料都需要適當的保護。
暫停 Buttom Halves 運作
單是暫停 bottom halves 運作,還不足以提供資料保護。通常,還必須加上抓取同步鎖的動作,才能確保資料無誤。
驅動程式需要同時執行這兩種動作。
要暫停所有 bottom halves 的運作。
| 函式 | 說明 |
|---|---|
| void local_bh_disable() | 在當前處理器上禁用 softirq 與 tasklet 處理 |
| void local_bh_enable() | 在當前處理器上啟用 softirq 與 tasklet 處理 |
這兩個函式允許巢狀呼叫
只有在最後一個對應的 local_bh_enable() 呼叫可以打開先前關閉的後段處理。
這些函式藉操作一個 per-task 計數值 preempt_count 達成這個功能。當計數值變成零時,後段處理才可以進行。
因為執行 local_bh_enable() 前 bottom halves 處理暫停狀態,所以呼叫後也會順便檢查,並執行尚在等待中的推遲作業。
注意:
這類呼叫不會關閉 work queues 的執行。因為 work queues 執行於程序環境,不會引起非同步執行問題,所以不用關閉它。因為 softirqs 與 tasklets 都不時的啟動 (如中斷處理程式返回時),核心必須能適時暫停這些機制。
[Linux Kernel] ioremap, mmap
ioremap
驅動程式,不能夠直接存取實體記憶體,必須存取相對應的虛擬記憶體.

設定 Interface 暫存器,最後設定Device 的暫存器
mmap
應用分2種
1. 檔案對映到記憶體空間,高速存取.
2. 建立匿名映射,用於父子行程間共享內存
linux 驅動設備也是文件,但字符設備不支持 mmap 方法,因為字符設備和塊設備緩沖同步策略不一樣。

[Linux kernel] DMA
DMA的操作是需要物理地址的,但是在linux内核中使用的都是虚拟地址,如果我们想要用DMA对一段内存进行操作,我们如何得到这一段内存的物理地址和虚拟地址的映射呢?dma_alloc_coherent这个函数实现了这种机制。
1、函数原型: void *dma_alloc_coherent( struct device *dev, size_t size,dma_addr_t *dma_handle,gfp_t gfp);
下面的这一段参考 http://blog.csdn.net/lanmanck/archive/2009/11/05/4773175.aspx
2、调用
A = dma_alloc_writecombine(B,C,D,GFP_KERNEL);
含义:
A: 内存的虚拟起始地址,在内核要用此地址来操作所分配的内存
B: struct device指针,可以平台初始化里指定,主要是dma_mask之类,可参考framebuffer
C: 实际分配大小,传入dma_map_size即可
D: 返回的内存物理地址,dma就可以用。
所以,A和D是一一对应的,只不过,A是虚拟地址,而D是物理地址。对任意一个操作都将改变缓冲区内容
/* Allocate TX and RX buffers for DMA channels */ bu92747kv_ir->rx_buff_virt = dma_alloc_coherent(NULL, FIFO_SIZE, &(bu92747kv_ir->rx_buf_dma_phys), GFP_KERNEL | GFP_DMA);

Sleep 與 Wake Up
Monday, January 10, 2022
[Linux kernel] SPI 實作
Linux SPI 子系統將驅動程式分為三種類型
SPI bus driver:主要目的為提供 API 給下層的 master driver 及上層的 protocol driver (稍後會提) 註冊,並傳
送封包至下層的 driver。 (spi_device)SPI Master driver:主要工作為初始化控制器,並負責對暫存器寫入以及中斷處理
SPI protocol driver :主要為發送 SPI 訊息封包至所選擇的裝置。
訊息封包的格式定義在 spi.h 的 spi_message 結構中
==============================================
struct spi_message {
struct list_head transfers;
struct spi_device *spi;
unsgined is_dma_mapped
/* completion is reported through a callback */
void (*complete)(void *context);
void *context;
unsigned actual_length;
int status;
list_head queue;
void *state;
}
==============================================
呼叫 spi_sync 以起始傳送
或者也可直接呼叫 spi_read/spi_write
在平台初始化時預先定義系統包含那些 SPI 周邊,而子系統也定義一個結構 spi_board_info 提供給開發者填入相對應的資訊
==============================================
static struct spi_board_info devkit8000_spi_board_info[] __initdata = {
{
/* [PDA9320]TSC3006 TouchScreen Driver Porting
.modalias= "tsc2006", //"ads7846",
.bus_num= 3, //2,
.chip_select= 0,
.max_speed_hz= 1500000,
.controller_data= &tsc2006_mcspi_config, //&ads7846_mcspi_config,
.irq= OMAP_GPIO_IRQ(OMAP3_DEVKIT_TS_GPIO),
.platform_data= &tsc2006_config, //&ads7846_config,
}
};
==============================================
modalias 欄位的值必須與 protocol driver 註冊的名字相同
[Linux kernel] SPI 理論
SPI (Serial Peripheral Interface) 是一種串列式的 I/O 介面,時脈約 1~ 70MHz,在微控制器和低速裝置之間提供一個低成本、易使用的介面,進行同步串行資料傳輸,包括 FLASH, ADC, PLL, RTC, LIU, CODEC... 都可以用 SPI 介面來控制。


SPI 相當容易實作, 但各家採用的 SPI 又不盡相同, 有正緣、負緣、傳輸的數據為 8-bit、16-bit、四線、三線... 多種變形。要將每一種都實作一遍也不難, 但如何能夠共用模組, 減少重複的驗證及除錯, 避免 re-invent the wheel 才是工程師不得多花一點心思的地方。
一種四線制串列匯流排介面,為主 / 從結構,四條導線分別為
串列時脈 (SCLK/SCK) - 時鐘信號,由主裝置產生
主出從入 (MOSI) - 主裝置資料輸出,從裝置資料輸入 (Master Output Slave Input)
主入從出 (MISO)- 主裝置資料輸入,從裝置資料輸出 (Slave Output Master Input)
從選 (SS) 訊號 - 從裝置 Enable 信號,由主裝置控制 (Slave Single)
主元件為時脈提供者,可發起讀取從元件或寫入從元件作業。這時主元件將與一個從元件進行對話。當匯流排上存在多個從元件時,要發起一次傳輸,主元件將把該從元件選擇線拉低,然後分別透過 MOSI 和 MISO 線路啟動數據發送或接收。
SPI 總線工作方式
SPI 總線有四種工作方式,其中使用的最為廣泛的是 SPI0 和 SPI3 方式(實線表示):
時序詳解:
CPOL:時鐘極性 (Polarity) 選擇
為 0 時 SPI 總線空閒為低電位
為 1 時 SPI 總線空閒為高電位
為 0 時在 SCK 第一個周期 MISO 輸入
為 1 時在 SCK 第二個周期 MISO 輸入
當 CPHA=0、CPOL=0 時
MISO 引腳上的資料在第一個 SPSCK 周期之前已經輸入了,而為了保證正確傳輸,MOSI 引腳的 MSB 位必須與SPSCK 的第一個周期邊緣同步
在 SPI 傳輸過程中,首先將資料輸入,然後在同步時鐘信號的正緣觸發時,SPI 的接收方捕捉位信號,在 clock 信號的一個週期結束時 (負緣觸發),下一筆資料輸入,再重複上述過程,直到一個字元的 8 位信號傳輸結束。
當 CPHA=0、CPOL=1 時
與前者唯一不同之處只是在同步 clock 信號的負緣觸發信號,正緣觸發時,下一筆資料輸入
當 CPHA=1、CPOL=0 時
MISO 引腳和 MOSI 引腳上的資料的 MSB 位必須與 SPSCK 的第一個邊沿同步,在 SPI 傳輸過程中,在同步 clock 信號週期開始時 (正緣觸發) 資料輸入,然後在同步 clock 信號的負緣觸發時,SPI 的接收方捕捉位信號,在 clock 信號的一個週期結束時 (正緣觸發),下一筆資料輸入,再重複上述過程,直到一個字元的 8 位信號傳輸結束。
當 CPHA=1、CPOL=1 時
與前者唯一不同之處只是在同步時鐘信號的正緣觸發,負緣觸發信號時,下一筆資料輸入
參考
kernel/Documentation/spi/spi-summary (Salve Devices)
http://ww2.cs.fsu.edu/~rosentha/linux/2.6.26.5/docs/DocBook/kernel-api/ch25.html
http://www.eettaiwan.com/SEARCH/ART/SPI.HTM
http://tw.myblog.yahoo.com/louis99lin/article?mid=109&prev=117&next=-1
http://avr.eefocus.com/article/10-08/2075521282652436.html
http://en.wikipedia.org/wiki/Serial_Peripheral_Interface_Bus
[C] struct 初始值寫法
typedef struct _DInfo
{
unsigned char u8AsudSys;
unsigned char u8CcolorSys;
std::string frequency;
std::string Width;
std::string Name;
int bUpdate;
_DvbtcSearchInfo()
{
u8AsudSys = 0;
u8CcolorSys = 0;
frequency = "";
Width = "";
Name = "";
bUpdate = 0;
}
} DInfo;
Sunday, January 9, 2022
[Linux Kernel] 原子操作与同步机制
现代操作系统支持多任务的并发,并发在提高计算资源利用率的同时也带来了资源竞争的问题。例如C语言语句“count++;”在未经编译器优化时生成的汇编代码为。

当操作系统内存在多个进程同时执行这段代码时,就可能带来并发问题

假设count变量初始值为0。
进程1执行完“mov eax, [count]”后,寄存器eax内保存了count的值0。此时
进程2被调度执行,抢占了进程1的CPU的控制权。进程2执行“count++;”的汇编代码,将累加后的count值1写回到内存。然后,进程1再次被调度执行,CPU控制权回到进程1。
进程1接着执行,计算count的累加值仍为1,写回到内存。虽然进程1和进程2执行了两次“count++;”操作,但是count实际的内存值为1,而不是2!
單處理器原子操作
解决这个问题的方法是,将“count++;”语句翻译为单指令操作。
Intel x86指令集支持内存操作数的inc操作,这样“count++;”操作可以在一条指令内完成。因为进程的上下文切换是在总是在一条指令执行完成后,所以不会出现上述的并发问题。对于单处理器来说,一条处理器指令就是一个原子操作。 多处理器原子操作
多處理器原子操作
但是在多处理器的环境下,例如SMP架构,这个结论不再成立。我们知道“inc [count]”指令的执行过程分为三步:
1)从内存将count的数据读取到cpu。
2)累加读取的值。
3)将修改的值写回count内存。
这又回到前面并发问题类似的情况,只不过此时并发的主题不再是进程,而是处理器。
Intel x86指令集提供了指令前缀lock用于锁定前端串行总线(FSB),保证了指令执行时不会受到其他处理器的干扰。
Reference:
https://www.cnblogs.com/fanzhidongyzby/p/3654855.html
[Linux Kernel] 重入
printf() 為什麼有重入和效能上的問題
不可重入函式不可以在它還沒有返回就再次被呼叫。例如printf,malloc,free等都是不可重入函式。
因為中斷可能在任何時候發生,例如在printf執行過程中,因此不能在中斷處理函式裡呼叫printf,否則printf將會被重入。
函式不可重入大多數是因為在函式中引用了全域性變數。例如,printf會引用全域性變數stdout,malloc,free會引用全域性的記憶體分配表
常見的不可重入函式有:
printf --------引用全域性變數stdout
malloc --------全域性記憶體分配表
free --------全域性記憶體分配表
其實很簡單,只要遵守了幾條很容易理解的規則,那麼寫出來的函式就是可重入的。
第一,不要使用全域性變數。因為別的程式碼很可能覆蓋這些變數值。
第二,在和硬體發生互動的時候,切記執行類似disinterrupt()之類的操作,就是關閉硬體中斷。完成互動記得開啟中斷,在有些系列上,這叫做“進入/退出核心”或者用OS_ENTER_KERNAL/OS_EXIT_KERNAL來描述。
第三,不能呼叫任何不可重入的函式。
第四,謹慎使用堆疊。最好先在使用前先OS_ENTER_KERNAL。
還有一些規則,都是很好理解的,總之,時刻記住一句話:保證中斷是安全的!
通俗的來講吧:由於中斷是可能隨時發生的,斷點位置也是無法預期的。所以必須保證每個函式都具有不被中斷發生,壓棧,轉向ISR,彈棧後繼續執行影響的穩定性。也就是說具有不會被中斷影響的能力。既然有這個要求,你提供和編寫的每個函式就不能拿公共的資源或者是變數來使用,因為該函式使用的同時,ISR(中斷服務程式)也可那會去修改或者是獲取這個資源,從而有可能使中斷返回之後,這部分公用的資源已經面目全非。
滿足下列條件的函式多數是不可重入的:
(1)函式體內使用了靜態的資料結構;
(2)函式體內呼叫了malloc()或者free()函式;
(3)函式體內呼叫了標準I/O函式。
非可重入函式1
char cTemp; // 全域性變數
void SwapChar1(char* lpcX, char* lpcY)
{
cTemp = *lpcX;
*lpcX = *lpcY;
lpcY = cTemp; // 訪問了全域性變數,在分享記憶體的多個執行緒中可能造成問題
}
非可重入函式2
void SwapChar2(char* lpcX, char* lpcY)
{
static char cTemp; // 靜態區域性變數
cTemp = *lpcX;
*lpcX = *lpcY;
lpcY = cTemp; // 使用了靜態區域性變數,在分享記憶體的多個執行緒中可能造成問題
}
性能上的問題:
上述的問題也屬於性能問題。對於併發或同時執行的多進程或任務,若要正確使用printf()函數,必須互斥使用,在一個進程或任務執行printf ()時,其他使用printf()的進程或任務只能等待,不能及時顯示。
Linux Kernel
Communcation with kernel space and user space
user space/kernel space 的IO觀念及實作
softirq、tasklet、workqueue之間的區別
Saturday, January 8, 2022
[sed & awk] 找出空密碼帳號
有些系統用戶並沒有設定密碼,基於安全考慮,最好找出所有空密碼的帳號並暫時禁止登入。在 FreeBSD 可以透過 awk 在檔案 /etc/master.password 找出空密碼帳號,切換到 root 並輸入以下指令:
# awk -F: 'NF > 1 && $1 !~ /^[#+-]/ && $2=="" {print $0}' /etc/master.passwd
|
以上指令會用 awk 掃瞄 /etc/master.passwd,並以 : 作為分隔字串。並且找出 password 欄位 ($2) 空白的內容。如果系統內有空密碼帳號,便會用以下格式顯示:
username::1099:1099::0:0:User &:/home/username:/bin/bash |
當發現有空密碼帳號後,可以用以下指令進行 lock 及 unlock 的動作:
lock user # pw lock username unlock user # pw unlock username |
[sed & awk] 混合使用 sed and awk 尋找
nameState 所泄生的輸出被接管送到 awk 程式,以便抽取出每筆紀錄。
list
root@ubuntu:/media/sf_share/sedawk_progs/sedawk2progs/ch02# cat list John Daggett, 341 King Road, Plymouth MA Alice Ford, 22 East Broadway, Richmond VA Orville Thomas, 11345 Oak Bridge Road, Tulsa OK Terry Kalkas, 402 Lans Road, Beaver Falls PA Eric Adams, 20 Post Road, Sudbury MA Hubert Sims, 328A Brook Road, Roanoke VA Amy Wilde, 334 Bayshore Pkwy, Mountain View CA Sal Carpenter, 73 6th Street, Boston MA |
nameState
s/ CA/, California/ s/ MA/, Massachusetts/ s/ OK/, Oklahoma/ s/ PA/, Pennsylvania/ s/ VA/, Virginia/ |
結果
root@ubuntu:/media/sf_share/sedawk_progs/sedawk2progs/ch02# sed -f nameState list | awk -F, '{print $4}' |
列出每一個州名,並在其後印出每一個居民的名字。
這個 shell 命令稿分成三部分
首先呼叫 awk 以產生待排序的資料,當作 sort 之輸入
再呼叫 awk 測試排序好的輸入資料,以判斷當前紀錄中的州名是否與先前的紀錄重覆
byState
#! /bin/sh
awk -F, '{
print $4 ", " $0
}' $* |
sort |
awk -F, '
$1 == LastState {
print "\t" $2
}
$1 != LastState {
LastState = $1
print $1
print "\t" $2
}'
|
root@ubuntu:/media/sf_share/sedawk_progs/sedawk2progs/ch02# sed -f nameState list | ./byState
California
Amy Wilde
Massachusetts
Eric Adams
John Daggett
Sal Carpenter
Oklahoma
Orville Thomas
Pennsylvania
Terry Kalkas
Virginia
Alice Ford
Hubert Sims |
工作原理
root@ubuntu:/media/sf_share/sedawk_progs/sedawk2progs/ch02# sed -f nameState list | awk -F, '{print $4 ", " $0}'
Massachusetts, John Daggett, 341 King Road, Plymouth, Massachusetts
Virginia, Alice Ford, 22 East Broadway, Richmond, Virginia
Oklahoma, Orville Thomas, 11345 Oak Bridge Road, Tulsa, Oklahoma
Pennsylvania, Terry Kalkas, 402 Lans Road, Beaver Falls, Pennsylvania
Massachusetts, Eric Adams, 20 Post Road, Sudbury, Massachusetts
Virginia, Hubert Sims, 328A Brook Road, Roanoke, Virginia
California, Amy Wilde, 334 Bayshore Pkwy, Mountain View, California
Massachusetts, Sal Carpenter, 73 6th Street, Boston, Massachusetts |
預設的狀況下,程式 sort 會依字母順序排序每個輸入列,並從左到右檢視其中每個字元。
root@ubuntu:/media/sf_share/sedawk_progs/sedawk2progs/ch02# sed -f nameState list | awk -F, '{print $4 ", " $0}' | sort
California, Amy Wilde, 334 Bayshore Pkwy, Mountain View, California
Massachusetts, Eric Adams, 20 Post Road, Sudbury, Massachusetts
Massachusetts, John Daggett, 341 King Road, Plymouth, Massachusetts
Massachusetts, Sal Carpenter, 73 6th Street, Boston, Massachusetts
Oklahoma, Orville Thomas, 11345 Oak Bridge Road, Tulsa, Oklahoma
Pennsylvania, Terry Kalkas, 402 Lans Road, Beaver Falls, Pennsylvania
Virginia, Alice Ford, 22 East Broadway, Richmond, Virginia
Virginia, Hubert Sims, 328A Brook Road, Roanoke, Virginia |
為了依照州名順序重新排列紀錄,因此我們將州名加到每筆紀錄的起頭,當作排序的關鍵欄位。
配合 SVN ST
svn st | awk '{if ( $1 == "M") { print $0}}' |
awk
awk 是一種處理資料且可產生報告的語言,功能相當強大。
awk 的作用格式
awk '樣式' 檔案 : 符合樣式的列顯示出來
awk '{動作}' 檔案 : 對每一列都執行{}中的動作
awk '樣式{動作}' 檔案: 符合樣式的列,執行{}中的動作
awk 的作用法 1
awk '/La/' dataf3
顯示含 La 的列
awk 的作用法 2
awk '{ print $1, $2 }' dataf3
顯示每一列的第 1 及第 2 欄
awk 的作用法 3
awk '/La/{ print $1, $2 }' dataf3
將含有 La 的列的第 1 及第 2 欄顯示出來
awk 的作用法 4
awk -F: '/ols3/{ print $3, $4 }' /etc/passwd
以 : 為分隔字元,將 passwd 檔中的 ols3 使用者的 uid 及 gid 顯示出來
awk 的作用法 5
awk -F: 'BEGIN{OFS="+++"}/ols3/{ print $1, $2, $3, $4, $5 }' /etc/passwd
以 : 為分隔字元,將 passwd 檔中的 ols3 使用者的第 1~5 欄顯示出來,且顯示的分隔符號設為 +++
輸出結果:ols3+++x+++500+++500+++
BEGIN{} 用來指示 awk 一開始做一些初始化的設定,OFS="+++" 是設定輸入欄位間的分隔符號之意
Friday, January 7, 2022
[c] void*
A pointer to void is a "generic" pointer type. A void * can be converted to any other pointer type without an explicit cast. You cannot dereference a void * or do pointer arithmetic with it; you must convert it to a pointer to a complete data type first.
void * is often used in places where you need to be able to work with different pointer types in the same code. One commonly cited example is the library function qsort:
==========================================================
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *));
==========================================================
base is the address of an array, nmemb is the number of elements in the array, size is the size of each element, and compar is a pointer to a function that compares two elements of the array. It gets called like so:
==========================================================
int iArr[10];
double dArr[30];
long lArr[50];
...
qsort(iArr, sizeof iArr/sizeof iArr[0], sizeof iArr[0], compareInt);
qsort(dArr, sizeof dArr/sizeof dArr[0], sizeof dArr[0], compareDouble);
qsort(lArr, sizeof lArr/sizeof lArr[0], sizeof lArr[0], compareLong);
==========================================================
The array expressions iArr, dArr, and lArr are implicitly converted from array types to pointer types in the function call, and each is implicitly converted from "pointer to int/double/long" to "pointer to void".
The comparison functions would look something like:
==========================================================
int compareInt(const void *lhs, const void *rhs)
{
const int *x = lhs; // convert void * to int * by assignment
const int *y = rhs;
if (*x > *y) return 1;
if (*x == *y) return 0;
return -1;
}
==========================================================
By accepting void *, qsort can work with arrays of any type.
The disadvantage of using void * is that you throw type safety out the window and into oncoming traffic. There's nothing to protect you from using the wrong comparison routine:
==========================================================
qsort(dArr, sizeof dArr/sizeof dArr[0], sizeof dArr[0], compareInt);
==========================================================
compareInt is expecting its arguments to be pointing to ints, but is actually working with doubles. There's no way to catch this problem at compile time; you'll just wind up with a missorted array.
example:
/******************************************************************************
Welcome to GDB Online.
GDB online is an online compiler and debugger tool for C, C++, Python, PHP, Ruby,
C#, VB, Perl, Swift, Prolog, Javascript, Pascal, HTML, CSS, JS
Code, Compile, Run and Debug online from anywhere in world.
*******************************************************************************/
#include <stdio.h>
typedef struct
{
int one;
int two;
int three;
} myStruct2;
typedef struct
{
int one;
int two;
} myStruct;
int
main ()
{
void *a = (void *) sizeof (myStruct2);
char *b = (char *)a;
printf ("a :%p\n", a);
b = b + sizeof (myStruct);
printf ("b :%p\n", b);
// Print the sizeof integer
printf("Size of (void*) = %lu"
" bytes\n",
sizeof(void*));
// Print the size of (int*)
printf("Size of (char*) = %lu"
" bytes\n",
sizeof(char*));
return 0;
}
a :0xc
b :0x14
Size of (void*) = 8 bytes
Size of (char*) = 8 bytes
void体现了一种抽象,这个世界上的变量都是"有类型"的。void的出现只是为了一种抽象的需要,如果你正确地理解了面向对象中"抽象基类"的概念,也很容易理解void数据类型。
Monday, January 3, 2022
[Linux Kernel] Interrupt(中斷)處理機制
處理器與外圍裝置進行通訊有兩種方式
1. 輪詢(效率低下)
2. 中斷
中斷原理
當我們在敲擊鍵盤的時候,鍵盤控制器會發送一箇中斷給處理器,告訴OS有中斷產生,處理器停下當前的工作,轉而由內 核呼叫中斷服務程式。(中斷控制器傳送中斷給處理器的時候,處理器根據中斷號查詢中斷向量表,找到中斷服務程式的入口地址,才能去執行中斷服務程式)。
中斷 (Interrupt) 介紹
中斷是現今對稱多處理中重要的機制,一般 CPU 同一時間只能處理一個指令,當這個 CPU 被某個行程占用時,只有透過中斷來讓CPU處理其他行程的指令。一般作業系統的中斷分為硬體和軟體中斷:
硬體中斷:
1. 在硬體週邊設備需要 CPU 時(例如,要跟 CPU 要資料,或是有資料要給 CPU),會對 CPU 發出中斷要求
2. CPU運行某個指令,發生錯誤,應而被迫中斷。或者由I/O發起硬體訊號,而將CPU中斷。
軟體中斷:
CPU執行組合語言中的中斷指令(像是 INT 3)
例外(exceptions)分為三種
程式錯誤例外
程式錯誤例外是在處理器偵測到程式有不合法的行為,或是作業系統發生某些錯誤時,由處理器自動發出的例外。這種例外又可分為三種:faults、traps、和 aborts。
軟體產生例外
由 INTO、INT3、和 BOUND 指令產生的。例如,INT3 命令會發出一個「程式中斷點」的例外。用 INT n 指令也可以「模擬」例外,但是,例外發生時,處理器會把錯誤碼推入堆疊中,而 INT n 指令則不會
所以,如果直接使用 INT n 指令呼叫例外處理程序,則該程序會從堆疊中取出錯誤碼,而在返回時,會回到錯誤的位址。
機器錯誤例外
在 Pentium 以後的處理器,可以檢查其內部是否有錯誤。在處理器有錯誤時,會產生機器錯誤例外。
中斷向量
中斷和例外是利用一個數字來區分不同的中斷或例外,這個數字稱為「中斷向量」(interrupt vector)。中斷向量是一個由 00H 到 FFH 的數字。其中,00H 到 1FH 的中斷向量是保留作系統用途的,不可任意使用;而其它的中斷向量則可以自由使用。保留的中斷向量如下表所示:
| 向量編號 | 助憶碼 | 說明 | 型態 | 錯誤碼 | 來源 |
| 00H | #DE | 除法錯誤 | Fault | 無 | DIV 和 IDIV 指令。 |
| 01H | #DB | 除錯 | Fault/Trap | 無 | 任何對程式或資料的參考、或是 INT 1 指令。 |
| 02H | - | NMI 中斷 | Interrupt | 無 | 不可遮罩的外部中斷。 |
| 03H | #BP | 中斷點 | Trap | 無 | INT3 指令。 |
| 04H | #OF | 溢出 | Trap | 無 | INTO 指令。 |
| 05H | #BR | 超出 BOUND 範圍 | Fault | 無 | BOUND 指令。 |
| 06H | #UD | 非法的指令 | Fault | 無 | UD2 或未定義的指令碼。 |
| 07H | #NM | 沒有 FPU | Fault | 無 | 浮點運算指令或 WAIT/FWAIT 指令。 |
| 08H | #DF | 雙重錯誤 | Fault | 有 | 任何會產生例外的指令。 |
| 09H | - | 保留 | Fault | 無 | 386 以後的處理器不產生此例外。 |
| 0AH | #TS | 不合法的 TSS | Fault | 有 | 工作切換、或存取 TSS。 |
| 0BH | #NP | 分段不存在 | Fault | 有 | 載入或存取分段。 |
| 0CH | #SS | 堆疊分段錯誤 | Fault | 有 | 載入 SS 載存器或存取堆疊。 |
| 0DH | #GP | 一般性錯誤 | Fault | 有 | 存取記憶體或進行其它保護檢查。 |
| 0EH | #PF | 分頁錯誤 | Fault | 有 | 存取記憶體。 |
| 0FH | - | 保留 | |||
| 10H | #MF | 浮點運算錯誤 | Fault | 無 | 浮點運算指令或 WAIT/FWAIT 指令。 |
| 11H | #AC | 對齊檢查 | Fault | 有 | 存取記憶體。 |
| 12H | #MC | 機器檢查 | Abort | 無 | 和機器型號有關。 |
| 13H ~ 1FH | - | 保留 | |||
| 20H ~ FFH | - | 自由使用 |
中斷處理程式
1,在響應中斷的時候,核心會執行一個函式--中斷服務程式(interrupt handler)或者叫做中斷服務例程(interrupt service routine,ISR)。中斷處理程式是裝置驅動程式的一部分。
2,中斷處理程式與核心其他函式的區別在於:中斷處理程式是由核心呼叫來響應中斷的,運行於中斷上下文(interrupt context)。
3,中斷處理程式應該儘量快的執行,儘可能快地恢復中斷程式碼的執行。
上半部與下半部的對比
又想讓中斷服務程式儘量快地執行,同時又想讓程式完成儘可能多的工作,這兩個目標顯然是有矛盾的,基於這樣的矛盾,我們把中斷服務程式劃分為兩個部分:上半部(top half)和下半部(bottom half)。
1,上半部:接收到一箇中斷就馬上開始執行,具有嚴格的時限要求,比如 對硬體裝置的響應和對硬體進行復位,這些工作都是在所有中斷被禁止 的情況下完成的。中斷服務程式是上半部。
2,下半部:沒有特別嚴格的時限要求,允許稍後完成的工作被劃分到下半部來做。一般來說中斷服務程式返回的時候會立刻執行下半部。
註冊中斷服務程式
驅動程式通過以下的函式來註冊一箇中斷服務程式:
int request_irq(unsigned int irq,//中斷號
irqreturn_t (*handler)(int,void *,struct pt_regs*),//中斷服務程式
unsigned long irqflags,
const char *devname,//產生中斷的裝置名
void *dev_id)
1,irqflags引數可以是0,也可是幾個掩碼(SA_INTERRUPT,SA_SAMPLE_RANDOM,SA_SHIRQ)的或操作。
SA_INTERRUPT:表明該中斷處理程式是快速中斷處理程式(fast interrupt handler)。加此標誌說明中斷服務程式在禁止 所有中斷的情況之下執行。如果沒有這個標誌的話,除了正在執行的中斷服務程式對應的那條中斷線遮蔽之外,其他的中斷都是處於啟用狀態。
SA_SAMPLE_RANDOM:(待考查)。
SA_SHIRQ:表示可以在多箇中斷處理程式間共享中斷線。在同一個中斷線上的每個中斷處理程式必須設定該標誌。
2,dev_id主要用於共享中斷線。當一箇中斷處理程式需要釋放的時候,dev_id將提供唯一的資訊,用於標識具體刪除哪個中斷處理程式,如果沒有該標誌,核心無法知道同一個中斷線上到底要刪除哪個中斷服務程式。如果無需共享中斷線,那麼該指標設定為NULL即可。
request_irq如果呼叫成功則返回0,失敗的話返回非0,最常見的是返回_EBUSY,表示此時中斷線正在被使用,或者沒有設定SA_SHIRQ標誌。
***********************注意點**********************
request_irq函式可能導致睡眠,所以該函式不能用在中斷上下文和不能阻塞的程序中。原因是:在註冊中斷處理程式的過程中,核心需要在/proc/irq檔案建立一個與中斷對應的項,proc_makedir ()就是用來建立新的procfs項的。proc_makedir()通過proc_create()來對procfs進行設定,而proc_create()會呼叫kmalloc()來請求分配記憶體。而kmalloc()是可以睡眠的。
************************注意點*********************
釋放中斷處理程式:
void free_irq(unsigned int irq,void *dev_id);
如果指定的中斷線未設定共享標誌,那麼在刪除中斷處理程式的同時禁用這條中斷線,如果中斷線是共享的,那麼根據dev_id來刪除指定的中斷處理程式。而只有等到該中斷線上的所有中斷處理程式都刪除完了才會禁用該中斷線。
六,編寫中斷處理程式
1,static irqreturn_t (*handler)(int irq,void *dev_id,struct pt_regs* regs)irq指中斷號,dev_id和request_irq中的dev_id必須一致。
以 Linux 為例,interupt 分成 2 部分

中斷上下文
當執行一箇中斷處理程式或者下半部時,核心執行在中斷上下文。因為中斷沒有程序的背景,所以中斷上下文中不能睡眠(核心排程的單位是程序,要進行的是程序上下文切換)。另外,中斷處理程式並沒有自己的棧,它共享被中斷程序的核心棧。如果沒有正在執行的程序,它就使用idle程序棧。
中斷下半部 (bottom half)
可以推遲的工作
一,什麼是下半部?下半部就是與中斷處理密切相關,但是中斷處理程式本身不執行的工作。
二,為什麼要用下半部?中斷處理程式執行的時間應該儘量的短,因為在中斷服務例程執行期間,當前的中斷線會被遮蔽(如果設置了SA_INTTERUPT則會遮蔽所有的中斷),這樣其他的中斷就極有可能無法得到處理器的響應。為此,為了儘量縮短中斷服務程式的執行,我們要把一些對時間要求不嚴格的工作推遲去作。這就是為什麼需要使用下半部的原因。
三,下半部實現方法
有軟中斷、tasklet、工作佇列 (workqueue)
其中 tasklet 是基於軟中斷實現的。
軟中斷是一組靜態定義的下半部介面,一共有32個,可以在所有處理器上同時執行(甚至相同型別的軟中斷可以同時執行)。
tasklet則沒有這麼寬鬆的條件--相同型別的 tasklet 是不能同時執行的。對於大部分下半部處理來說,tasklet 就足夠了,像網路這樣要求非常高的才需要軟中斷。
另外,軟中斷是在編譯期靜態註冊的,而tasklet可以通過程式碼動態註冊。
四,軟中斷的實現
軟中斷由 softirq_action結構表示,定義在<linux/interrupt.h>中
struct softirq_action{
void (*action)(struct softirq_action*);//for process the bottom half
void *data;//parameter for the function above
在<kernel/softirq.c>中包含了擁有32個該結構成員的陣列,每個被註冊的softirq佔據陣列的一項,
所以,最多應該可以有32個softirq,這是一個定值,無法動態改變。
1,軟中斷處理程式action的函式原型
void softirq_handler(struct softirq_action*);
軟中斷不會被另外一個軟中斷搶佔,唯一可以搶佔軟中斷的只有中斷服務程式。但是,其他型別的軟
中斷,甚至是同類型的軟中斷可以在其他處理器上面執行。
2,執行軟中斷
一個軟中斷註冊之後只有被標記了才會執行,這被稱作觸發軟中斷(raising the softirq)。一般的,
中斷處理程式(上半部)在返回前會標記軟中斷,使其在稍後執行。
在 以下地方,softirq會被檢查和執行:
1)處理完一個硬體中斷(中斷服務程式上半部)
2)在ksoftirqd核心執行緒中
3)在那些顯示檢查和執行待處理的軟中斷的程式碼中,如網路子系統
不管是在什麼地方,以什麼樣的方式來喚起softirq,softirq都要在do_softirq()中執行。該函式
實現比較簡單,就是用迴圈遍歷待處理的softirq,每個都呼叫一下。
3,使用軟中斷
軟中斷留給系統中對時間有嚴格要求以及最重要的下半部使用,目前,只有網路子系統和SCSI直接使用軟中斷,像核心定時器和 tasklet 都是建立在軟中斷上的。
1)分配索引
在編譯期間,通過<linux/interrupt.h>中的列舉型別來靜態宣告一個軟中斷。核心用從0開始的索引來表示一種
相對優先順序。index小的比大的優先順序要高。建立一個新的軟中斷必須在此列舉型別中加入新的項。而且加入的的時候必須根據你希望賦予它的優先順序來決定加入到什麼位置。一般加入到網路相關的項之後,最後一項之前。
2)註冊軟中斷處理程式
在執行時通過open_softirq()註冊軟中斷處理程式。該函式有3個引數:軟中斷索引號,中斷處理函式指標,還有就是data資料域指標。
3)觸發軟中斷
在列舉型別列表中新增新項以及通過open_softirq()之後軟中斷服務程式就可以執行了,raising_softirq()函式
可以將軟中斷設定為一個掛起狀態,讓它在下次do_softirq()的時候投入執行。
五,Tasklets
tasklets是建立在軟中斷上的,換句話說,tasklets本身就是一種軟中斷。
tasklets由兩類軟中斷表示:HI_SOFTIRQ和TASKLET_SOFTIRQ,兩者的唯一區別就是前者比後者的優先順序高。
1,tasklet結構體,定義在<linux/interrupt.h>中
struct tasklet_struct{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
}
func函式指標是tasklet中斷處理函式,data是函式引數,state是tasklet的狀態,有0,TASKLET_STATE_SCHED和
TASKLET_STATE_RUN。TASKLET_STATE_SCHED表示tasklet已經被排程,準備投入執行,而TASKLET_STATE_RUN則
表示tasklet正在執行。count是引用計數器,當count不為0時,tasklet被禁止,為0時,tasklet才被啟用。
2,排程tasklets
已排程的tasklet存放在兩個單處理器資料結構:tasklet_vec和tasklet_hi_vec。這兩個結構都是由tasklet_struct
組成的,每一個節點代表不同的tasklet。
tasklets由tasklet_schedule()和tasklet_hi_schedule()函式進行呼叫。以下是tasklet_schedule()的執行細節:
1)如果tasklet的狀態是TASKLET_STATE_SCHED,則說明tasklet已經被排程,函式立即返回。
2)儲存中斷狀態,然後禁止中斷,這樣可以保證處理器資料不會混亂。
3)把需要排程的tasklet加到tasklet_vec或tasklet_hi_vec連結串列中。
4)喚起TASKLET_SOFTIRQ或HI_SOFTIRQ,這樣下一次在do_softirq()中就會執行該tasklet。
5)恢復中斷到原狀態並返回。
例外的型態
程式錯誤例外有三種:
- Fault:這種例外通常是可以更正的,而且在更正後,程式應該可以繼續無誤地進行。在發生 fault 時,處理器會回到造成 fault 指令之前的狀況。在堆疊中存放的返回位址,存放的是造成 fault 的指令的位址。所以,在例外處理完,返回原程式時,會重新執行原來造成 fault 的指令。正常的話,應該不會再產生 fault。例如,最常見的 fault 應該是分頁錯誤(Page-fault),分頁錯誤的處理程序應該要讀入所需要的分頁,再返回程式中,讓程式可以繼續執行。
- Trap:這種例外是在被 trap 的指令執行完後,立刻產生的。因此,它的返回位址是被 trap 的指令的下一個指令。在例外返回後,程式可以正確無誤地斷續執行。如果被 trap 的是一個跳躍指令(例如,JMP 指令)也不會有問題,它的返回位址會是 JMP 指令的目標。
- Abort:這種例外是非常嚴重的錯誤,沒有辦法返回原程式繼續執行。通常,只有在機器錯誤、或是在系統表格中有不一致或不合法的數值時,才會出現這種例外。這類例外的處理程序,應該是把錯誤發生時的狀態存下,並儘可能安全地關閉應用程式和系統。
因為在中斷或(有些)例外發生時,原程式必須能繼續執行,因此,中斷和例外一定是在指令和指令中間發生,而不會在指令進行的途中發生。
中斷服務需要注意哪些
1. 中断函数代码应尽量简洁。一般不宜在中断函数内编写大量复杂冗长的代码;应尽量避免在中断函数内调用其他自定义函数;
2、尽量避免在中断内调用数学函数。因为某些数学函数涉及相关的库函数调用和中间变量较多,可能出现交叉调用。在必须使用数学函数时,可考虑将复杂的数学函数运算任务交给主程序完成,中断函数通过全局变量引用其结果;
3、宏的定义与调用。在中断函数中调用宏,可减少在函数调用中压栈 (push) 与出栈 (pop) 的开销。
九个小注意事项
1、中断函数不能进行参数传递
2、中断函数没有返回值
3、在任何情况下都不能直接调用中断函数
4、中断函数使用浮点运算要保存浮点寄存器的状态。
5、如果在中断函数中调用了其它函数,则被调用函数所使用的寄存器必须与中断函数相同,被调函数最好设置为可重入的。
6、(可忽略)C51编译器对中断函数编译时会自动在程序开始和结束处加上相应的内容,具体如下:
在程序开始处对ACC、B、DPH、DPL和PSW入栈,结束时出栈。
中断函数未加using n修饰符的,开始时还要将R0~R1入栈,结束时出栈。
如中断函数加using n修饰符,则在开始将PSW入栈后还要修改PSW中的工作寄存器组选择位。
C51编译器从绝对地址8m 3处产生一个中断向量,其中m为中断号,也即interrupt后面的数字。该向量包含一个到中断函数入口地址的绝对跳转。
7、中断函数最好写在文件的尾部,并且禁止使用extern存储类型说明。防止其它程序调用。
8、在设计中断时,要注意的是哪些功能应该放在中断程序中,哪些功能应该放在主程序中。一般来说中断服务程序应该做最少量的工作,这样做有很多好处。
首先系统对中断的反应面更宽了,有些系统如果丢失中断或对中断反应太慢将产生十分严重的后果,这时有充足的时间等待中断是十分重要的。
其次它可使中断服务程序的结构简单,不容易出错。中断程序中放入的东西越多,他们之间越容易起冲突。简化中断服务程序意味着软件中将有更多的代码段,但可把这些都放入主程序中。
9、中断服务程序的设计对系统的成败有至关重要的作用,要仔细考虑各中断之间的关系和每个中断执行的时间,特别要注意那些对同一个数据进行操作的中断
举例说明
中断是嵌入式系统中重要的组成部分,这导致了很多编译开发商提供一种扩展—让标准C支持中断。具代表事实是,产生了一个新的关键字 __interrupt。下面的代码就使用了__interrupt关键字去定义了一个中断服务子程序(ISR),请评论一下这段代码的。
- __interrupt double compute_area (double radius)
- {
- double area = PI * radius * radius;
- printf("\nArea = %f", area);
- return area;
- }
这个函数有太多的错误了:
1) ISR 不能返回一个值。如果你不懂这个,那么你不会被雇用的。
2) ISR 不能传递参数。如果你没有看到这一点,你被雇用的机会等同第一项。
3) 在许多的处理器/编译器中,浮点一般都是不可重入的。有些处理器/编译器需要让额处的寄存器入栈,有些处理器/编译器就是不允许在ISR中做浮点运算。此外,ISR应该是短而有效率的,在ISR中做浮点运算是不明智的。
4) 与第三点一脉相承,printf()经常有重入和性能上的问题。如果你丢掉了第三和第四点,我不会太为难你的。不用说,如果你能得到后两点,那么你的被雇用前景越来越光明了。
https://www.itread01.com/content/1547179205.html
Subscribe to:
Comments (Atom)